Running an artificial intelligence locally on your device offers unparalleled privacy benefits, eliminating the need for costly API subscriptions or online access fees. In contrast to earlier AI coding assistants that were often buggy and sluggish, newer local models have made significant strides in performance and reliability, capable of rivaling their cloud-based counterparts when utilized judiciously.
The new coding model from Qwen has made a significant impact, with me relying on it approximately 50% of the time now.
Related ↗US AI models are being considered for access by trusted partners of the G7 leaders.02Local coding model Qwen 3.6-27b gains traction.
›Combine with VSCodium for an entirely open-source setup.
Local AI models abound, rapidly advancing with each iteration, yet often fall short of expectations. While some may offer sophisticated autocompletion features, their overall impact is limited compared to more robust coding tools.
Recent advancements have made these models more attractive than ever before. Qwen's coding-specific models are now viable on moderately priced hardware, offering a level of usability that was previously lacking. Code completion, refactoring, and test writing capabilities are all handled with a reasonable degree of proficiency. Planning is still recommended, but it's not necessary to do so if you prefer to write directly. The model's limitations become apparent when compared to its cloud-based counterparts, which possess significantly more intelligence and sophistication.
Read next ↗Gigabit internet purchase limited by a faulty switch port, restricting speed to 100Mbps unexpectedly.I operate VSCodium locally using the Cline extension, which presents a compact interface for inputting commands, reviewing code snippets and managing context windows. My primary reliance is on this setup for straightforward tasks, reserving more intricate projects or refactorings for Claude to conserve tokens effectively.
With Ollama at its core, accessing my local AI is now seamless across all devices connected to my home network, liberating me from being tethered to a single workstation. This flexibility extends even to mobile devices like my trusty laptop.
I operate VSCodium locally using theCline extension, which presents a compact interface for inputting commands, reviewing code snippets and managing context windows. My primary reliance is on this setup for straightforward tasks, reserving more intricate projects or refactorings for Claude to conserve tokens effectively.
14Local alternatives to cloud models offer greater affordability and control.
›Costs of usage are accumulating.
A cloud model's intelligence doesn't necessarily outweigh the importance of maintaining control over sensitive data. Privacy and security concerns take precedence, especially when dealing with proprietary company data or confidential client information. Running a model locally ensures your code remains on-site, safeguarding against potential breaches. This is crucial for protecting valuable assets.
Monthly expenses are a significant consideration. Major chat platforms like Claude and ChatGPT require payment for access, with some plans starting at $20 per month. However costs can escalate rapidly if users aren't mindful of their spending. Having a local agent in place eliminates the need for ongoing monthly subscriptions or token-based fees.
Owning a GPU means electricity costs become your sole recurring expense. Initially, this might seem like a questionable investment, but consider the Claude Max subscription, which starts at $100 for heavy coders. After twelve months, that's equivalent to an RTX 5080 purchase price. Two years you'd be looking at an RTX 5090, assuming one can still be found at its MSRP.
Having a self-sufficient infrastructure means you're not at the mercy of external server outages. I've personally experienced frustrating delays when trying to access Claude or Codex for coding tasks due to unforeseen server issues. With a local setup, however, you retain significant control over your productivity and availability.
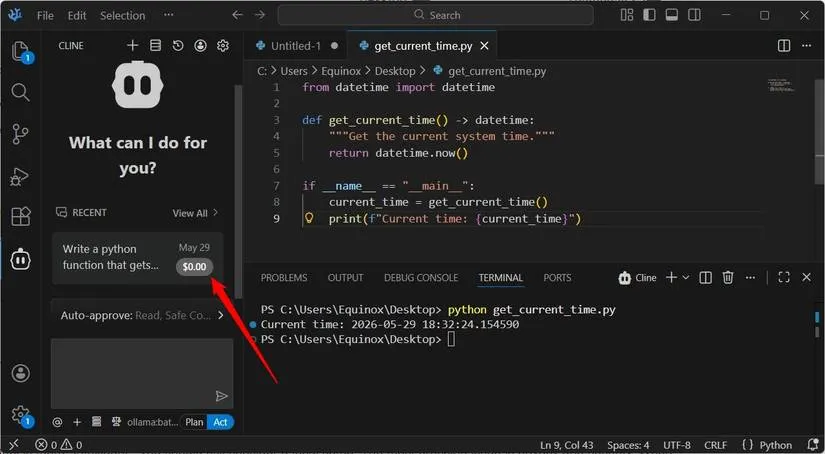
21Locally running a coding model comes with compromises.
›Memory capacity, data precision, and contextual understanding limitations.
Operating a localized AI model comes with inherent constraints, primarily driven by hardware limitations.
Running a mid-range consumer GPU, such as the 5070 Ti, will inevitably lead to performance limitations. The main bottleneck lies in the Video Random Access Memory (VRAM), which restricts both model size and contextual understanding capabilities.
Quantization techniques enable more efficient model compression. Terms like Q4 and Q8 indicate the level of compression achieved. Although a Q8 model boasts higher precision, its Q4 counterpart permits running larger models on hardware with limited VRAM, albeit at a minor sacrifice in output quality. With proper quantization, I can utilize 27B parameter models on my 5070Ti GPU, although more extensive models remain inaccessible.
Local processing often lags behind cloud-based models in terms of execution speed due to memory constraints on smaller devices. Complex tasks exceed the capacity of localized systems.

›Personal use of local coding models now viable.
Local Large Language Model (LLM) services have transitioned from mere novelties to practical tools, suitable for everyday use. Effective utilization hinges on seamless integration capabilities.
Consider integrating this local model into your workflow as a companion to cloud-based tools by linking it with VSCodium or your preferred IDE. This approach won't necessarily supplant top-tier models for all tasks, but having a personal, cost-free assistant on hand can significantly enhance your development experience.